Chapter 5 Exploitation rate diagnostic experiments
experiment_slug <- "2023-12-28-phylo-sampling-diag"
working_directory <- paste0(
"experiments/",
experiment_slug,
"/analysis/"
)
if (exists("bookdown_wd_prefix")) {
working_directory <- paste0(
bookdown_wd_prefix,
working_directory
)
}5.1 Dependencies
library(tidyverse)## ── Attaching core tidyverse packages ─────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
## ✔ purrr 1.0.2
## ── Conflicts ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(cowplot)##
## Attaching package: 'cowplot'
##
## The following object is masked from 'package:lubridate':
##
## stamplibrary(RColorBrewer)
library(khroma)
library(rstatix)##
## Attaching package: 'rstatix'
##
## The following object is masked from 'package:stats':
##
## filterlibrary(knitr)
source("https://gist.githubusercontent.com/benmarwick/2a1bb0133ff568cbe28d/raw/fb53bd97121f7f9ce947837ef1a4c65a73bffb3f/geom_flat_violin.R")print(version)## _
## platform aarch64-apple-darwin20
## arch aarch64
## os darwin20
## system aarch64, darwin20
## status
## major 4
## minor 2.1
## year 2022
## month 06
## day 23
## svn rev 82513
## language R
## version.string R version 4.2.1 (2022-06-23)
## nickname Funny-Looking Kid5.2 Setup
# Configure our default graphing theme
theme_set(theme_cowplot())
# Create a directory to store plots
plot_directory <- paste0(working_directory, "plots/")
dir.create(plot_directory, showWarnings=FALSE)
# Constants
focal_diagnostic <- "exploitation-rate"5.2.1 Load experiment summary data
summary_data_loc <- paste0(working_directory, "data/aggregate.csv")
summary_data <- read_csv(summary_data_loc)## Rows: 1080 Columns: 58
## ── Column specification ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (5): DIAGNOSTIC, EVAL_FIT_EST_MODE, EVAL_MODE, SELECTION, STOP_MODE
## dbl (53): ACCURACY, CREDIT, DIAGNOSTIC_DIMENSIONALITY, EVAL_MAX_PHYLO_SEARCH...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.summary_data <- summary_data %>%
mutate(
evals_per_gen = case_when(
EVAL_MODE == "cohort-full-compete" ~ 1.0 / NUM_COHORTS,
EVAL_MODE == "cohort" ~ 1.0 / NUM_COHORTS,
EVAL_MODE == "down-sample" ~ TEST_DOWNSAMPLE_RATE,
EVAL_MODE == "full" ~ 1.0,
EVAL_MODE == "indiv-rand-sample" ~ TEST_DOWNSAMPLE_RATE,
EVAL_MODE == "phylo-informed-sample" ~ TEST_DOWNSAMPLE_RATE
),
EVAL_FIT_EST_MODE = case_when(
EVAL_FIT_EST_MODE == "ancestor-opt" ~ "ancestor",
EVAL_FIT_EST_MODE == "relative-opt" ~ "relative",
.default = EVAL_FIT_EST_MODE
),
.keep = "all"
) %>%
mutate(
eval_label = case_when(
# Clean up down-sample label
EVAL_MODE == "down-sample" & EVAL_FIT_EST_MODE != "none" ~ paste("down-sample", EVAL_FIT_EST_MODE, sep="-"),
.default = EVAL_MODE
),
) %>%
mutate(
evals_per_gen = as.factor(evals_per_gen),
DIAGNOSTIC = as.factor(DIAGNOSTIC),
SELECTION = as.factor(SELECTION),
EVAL_MODE = as.factor(EVAL_MODE),
NUM_COHORTS = as.factor(NUM_COHORTS),
TEST_DOWNSAMPLE_RATE = as.factor(TEST_DOWNSAMPLE_RATE),
EVAL_FIT_EST_MODE = factor(
EVAL_FIT_EST_MODE,
levels = c(
"none",
"ancestor",
"relative"
),
labels = c(
"None",
"Ancestor",
"Relative"
)
)
)
# Grab just the exploitation rate data
exploit_summary_data <- filter(
summary_data,
DIAGNOSTIC == "exploitation-rate"
)5.2.2 Load experiment time series data
ts_data_loc <- paste0(working_directory, "data/time_series.csv")
ts_data <- read_csv(ts_data_loc)## Rows: 108000 Columns: 28
## ── Column specification ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): DIAGNOSTIC, EVAL_FIT_EST_MODE, EVAL_MODE, SELECTION
## dbl (24): NUM_COHORTS, SEED, TEST_DOWNSAMPLE_RATE, ave_depth, deleterious_st...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.ts_data <- ts_data %>%
mutate(
evals_per_gen = case_when(
EVAL_MODE == "cohort-full-compete" ~ 1.0 / NUM_COHORTS,
EVAL_MODE == "cohort" ~ 1.0 / NUM_COHORTS,
EVAL_MODE == "down-sample" ~ TEST_DOWNSAMPLE_RATE,
EVAL_MODE == "full" ~ 1.0,
EVAL_MODE == "indiv-rand-sample" ~ TEST_DOWNSAMPLE_RATE,
EVAL_MODE == "phylo-informed-sample" ~ TEST_DOWNSAMPLE_RATE
),
EVAL_FIT_EST_MODE = case_when(
EVAL_FIT_EST_MODE == "ancestor-opt" ~ "ancestor",
EVAL_FIT_EST_MODE == "relative-opt" ~ "relative",
.default = EVAL_FIT_EST_MODE
),
.keep = "all"
) %>%
mutate(
eval_label = case_when(
EVAL_MODE == "down-sample" & EVAL_FIT_EST_MODE != "none" ~ paste("down-sample", EVAL_FIT_EST_MODE, sep="-"),
.default = EVAL_MODE
)
) %>%
mutate(
evals_per_gen = as.factor(evals_per_gen),
DIAGNOSTIC = as.factor(DIAGNOSTIC),
SELECTION = as.factor(SELECTION),
EVAL_MODE = as.factor(EVAL_MODE),
NUM_COHORTS = as.factor(NUM_COHORTS),
TEST_DOWNSAMPLE_RATE = as.factor(TEST_DOWNSAMPLE_RATE),
EVAL_FIT_EST_MODE = factor(
EVAL_FIT_EST_MODE,
levels = c(
"none",
"ancestor",
"relative"
),
labels = c(
"None",
"Ancestor",
"Relative"
)
)
)
# Grab just the exploitation rate data
exploit_ts_data <- ts_data %>%
filter(DIAGNOSTIC == "exploitation-rate")Summarize time series data:
ts_summary_data <- ts_data %>%
group_by(SEED, DIAGNOSTIC, SELECTION, evals_per_gen, eval_label) %>%
summarize(
n = n(),
avg_num_unique_selected = mean(num_unique_selected),
total_optimal_trait_coverage_loss = sum(optimal_trait_coverage_loss)
)## `summarise()` has grouped output by 'SEED', 'DIAGNOSTIC', 'SELECTION',
## 'evals_per_gen'. You can override using the `.groups` argument.5.2.3 Plotting helper functions
The following function assist with exploratory plotting of different measurements from summary and time series data. Note that for these plots, standard lexicase reference is rendered at equivalent number of generations (instead of evaluations).
build_plot_summary_data <- function(data, diagnostic, selection, response) {
diag_data <- data %>% filter(DIAGNOSTIC == diagnostic)
full_median <- median(
filter(
diag_data,
eval_label == "full" & SELECTION == selection
)[[response]]
)
plot <- diag_data %>%
filter(
eval_label != "full" & SELECTION == selection
) %>%
ggplot(
aes_string(
x = "eval_label",
y = response,
fill = "eval_label"
)
) +
geom_hline(
yintercept = full_median,
size = 1.0,
alpha = 0.7,
color = "black",
linetype="dashed"
) +
geom_flat_violin(
position = position_nudge(x = .2, y = 0),
alpha = .8,
adjust = 1.5
) +
geom_point(
mapping = aes(color = eval_label),
position = position_jitter(width = .15),
size = .5,
alpha = 0.8
) +
geom_boxplot(
width = .1,
outlier.shape = NA,
alpha = 0.5
) +
scale_y_continuous(
# limits = c(-0.5, 100)
) +
scale_fill_bright() +
scale_color_bright() +
facet_grid(
SELECTION ~ evals_per_gen,
# nrow=2,
labeller = label_both
) +
theme(
legend.position = "none",
axis.text.x = element_text(
angle = 30,
hjust = 1
),
panel.border = element_rect(color = "gray", size = 2)
)
return(plot)
}
build_plot_time_series_single_sampling <- function(
data,
diagnostic,
selection,
sampling_level,
response
) {
diag_data <- data %>% filter(
DIAGNOSTIC == diagnostic &
SELECTION == selection &
evals_per_gen == sampling_level
) %>%
mutate(
sampling_level_label = sampling_level
)
full_diag_data <- data %>% filter(
DIAGNOSTIC == diagnostic & SELECTION == selection & eval_label == "full"
) %>%
mutate(
# Ensure that median line will sit in same facet
sampling_level_label = sampling_level
)
plot <- diag_data %>%
filter(
eval_label != "full"
) %>%
ggplot(
aes_string(
x = "ts_step",
# x = "evaluations",
y = {{ response }}
)
) +
stat_summary(
geom = "line",
fun = mean,
aes(
color = eval_label
)
) +
stat_summary(
geom = "ribbon",
fun.data = "mean_cl_boot",
fun.args = list(conf.int = 0.95),
alpha = 0.2,
linetype = 0,
aes(
color = eval_label,
fill = eval_label
)
) +
scale_fill_bright() +
scale_color_bright() +
# facet_wrap(
# ~ sampling_level_label,
# ncol = 1,
# labeller = label_both
# ) +
theme(
legend.position = "right"
) +
stat_summary(
data = full_diag_data,
geom = "line",
fun = median,
linetype = "dashed",
color = "black"
)
return(plot)
}
build_plot_time_series <- function(
data,
diagnostic,
selection,
response
) {
# Build 1% sampling plot and 10% sampling plot
p_01 <- data %>% build_plot_time_series_single_sampling(
diagnostic,
selection,
"0.01",
response
)
p_10 <- data %>% build_plot_time_series_single_sampling(
diagnostic,
selection,
"0.1",
response
)
title <- ggdraw() +
draw_label(
paste0(diagnostic, " - ", selection),
fontface = 'bold',
x = 0,
hjust = 0
) +
theme(
# add margin on the left of the drawing canvas,
# so title is aligned with left edge of first plot
plot.margin = margin(0, 0, 0, 7)
)
plot <- plot_grid(
title,
p_01 + labs(title = "1% subsampling") + theme(legend.position = "none"),
p_10 + labs(title = "10% subsampling") + theme(legend.position = "bottom"),
nrow = 3,
ncol = 1,
rel_heights = c(0.075, 1, 1)
)
return(plot)
}5.3 Aggregate score
5.3.1 Final - Lexicase selection
p <- summary_data %>% build_plot_summary_data(
"exploitation-rate",
"lexicase",
"elite_true_agg_score"
)## Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
## ℹ Please use tidy evaluation idioms with `aes()`.
## ℹ See also `vignette("ggplot2-in-packages")` for more information.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.## Warning: The `size` argument of `element_rect()` is deprecated as of ggplot2 3.4.0.
## ℹ Please use the `linewidth` argument instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.ggsave(
filename = paste0(plot_directory, "exploit-score-final-lex.pdf"),
plot = p + labs(title = "Exploitation rate - Lexicase selection"),
width = 15,
height = 10
)## Warning: Using the `size` aesthetic with geom_polygon was deprecated in ggplot2 3.4.0.
## ℹ Please use the `linewidth` aesthetic instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.5.3.2 Final - Tournament selection
p <- summary_data %>% build_plot_summary_data(
"exploitation-rate",
"tournament",
"elite_true_agg_score"
)
ggsave(
filename = paste0(plot_directory, "exploit-score-final-tourn.pdf"),
plot = p + labs(title = "Exploitation rate - Tournament selection"),
width = 15,
height = 10
)5.3.3 Statistical analysis
First, we’ll create a table of median / mean values for easy reference.
exploit_summary_data %>%
group_by(DIAGNOSTIC, SELECTION, evals_per_gen, eval_label) %>%
summarize(
score_median = median(elite_true_agg_score),
score_mean = mean(elite_true_agg_score),
replicates = n()
) %>%
kable()## `summarise()` has grouped output by 'DIAGNOSTIC', 'SELECTION', 'evals_per_gen'.
## You can override using the `.groups` argument.| DIAGNOSTIC | SELECTION | evals_per_gen | eval_label | score_median | score_mean | replicates |
|---|---|---|---|---|---|---|
| exploitation-rate | lexicase | 0.01 | down-sample | 9933.1800 | 9933.2455 | 20 |
| exploitation-rate | lexicase | 0.01 | down-sample-ancestor | 920.1625 | 913.6102 | 20 |
| exploitation-rate | lexicase | 0.01 | indiv-rand-sample | 2117.1200 | 2137.2725 | 20 |
| exploitation-rate | lexicase | 0.01 | phylo-informed-sample | 2157.9350 | 2162.8605 | 20 |
| exploitation-rate | lexicase | 0.1 | down-sample | 9967.3500 | 9968.1275 | 20 |
| exploitation-rate | lexicase | 0.1 | down-sample-ancestor | 6976.3600 | 6985.9325 | 20 |
| exploitation-rate | lexicase | 0.1 | indiv-rand-sample | 9360.5800 | 9360.2230 | 20 |
| exploitation-rate | lexicase | 0.1 | phylo-informed-sample | 9301.3500 | 9308.4105 | 20 |
| exploitation-rate | lexicase | 1 | full | 9981.7200 | 9982.2910 | 20 |
| exploitation-rate | tournament | 0.01 | down-sample | 9650.1650 | 9650.6660 | 20 |
| exploitation-rate | tournament | 0.01 | down-sample-ancestor | 1023.4150 | 1011.8228 | 20 |
| exploitation-rate | tournament | 0.01 | indiv-rand-sample | 9969.7650 | 9969.2945 | 20 |
| exploitation-rate | tournament | 0.01 | phylo-informed-sample | 9970.8950 | 9970.1455 | 20 |
| exploitation-rate | tournament | 0.1 | down-sample | 9972.3050 | 9972.0210 | 20 |
| exploitation-rate | tournament | 0.1 | down-sample-ancestor | 9988.9200 | 9988.9365 | 20 |
| exploitation-rate | tournament | 0.1 | indiv-rand-sample | 9999.8250 | 9999.8240 | 20 |
| exploitation-rate | tournament | 0.1 | phylo-informed-sample | 9999.7700 | 9999.7800 | 20 |
| exploitation-rate | tournament | 1 | full | 10000.0000 | 10000.0000 | 20 |
Next, we run a Kruskal-Wallis test to check for differences.
For these tests, we only compare within a single subsampling level (evals_per_gen) and within the same selection scheme.
kw_test <- exploit_summary_data %>%
filter(eval_label != "full") %>%
group_by(SELECTION, evals_per_gen) %>%
kruskal_test(elite_true_agg_score ~ eval_label) %>%
mutate(sig = (p < 0.05)) %>%
unite(
"comparison_group",
SELECTION,
evals_per_gen,
sep = "_",
remove = FALSE
)
kable(kw_test)| comparison_group | SELECTION | evals_per_gen | .y. | n | statistic | df | p | method | sig |
|---|---|---|---|---|---|---|---|---|---|
| lexicase_0.01 | lexicase | 0.01 | elite_true_agg_score | 80 | 67.04167 | 3 | 0 | Kruskal-Wallis | TRUE |
| lexicase_0.1 | lexicase | 0.1 | elite_true_agg_score | 80 | 68.10074 | 3 | 0 | Kruskal-Wallis | TRUE |
| tournament_0.01 | tournament | 0.01 | elite_true_agg_score | 80 | 66.76541 | 3 | 0 | Kruskal-Wallis | TRUE |
| tournament_0.1 | tournament | 0.1 | elite_true_agg_score | 80 | 67.17274 | 3 | 0 | Kruskal-Wallis | TRUE |
Perform pairwise wilcoxon rank-sum tests for all significant comparison groups.
# Grab group names of significant comparisons
sig_kw_groups <- filter(kw_test, p < 0.05)$comparison_group
wrs_test <- exploit_summary_data %>%
unite(
"comparison_group",
SELECTION,
evals_per_gen,
sep = "_",
remove = FALSE
) %>%
filter(
eval_label != "full" & comparison_group %in% sig_kw_groups
) %>%
group_by(SELECTION, evals_per_gen) %>%
pairwise_wilcox_test(elite_true_agg_score ~ eval_label) %>%
adjust_pvalue(method = "holm") %>%
add_significance("p.adj")
kable(wrs_test)| SELECTION | evals_per_gen | .y. | group1 | group2 | n1 | n2 | statistic | p | p.adj | p.adj.signif |
|---|---|---|---|---|---|---|---|---|---|---|
| lexicase | 0.01 | elite_true_agg_score | down-sample | down-sample-ancestor | 20 | 20 | 400 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.01 | elite_true_agg_score | down-sample | indiv-rand-sample | 20 | 20 | 400 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.01 | elite_true_agg_score | down-sample | phylo-informed-sample | 20 | 20 | 400 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.01 | elite_true_agg_score | down-sample-ancestor | indiv-rand-sample | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.01 | elite_true_agg_score | down-sample-ancestor | phylo-informed-sample | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.01 | elite_true_agg_score | indiv-rand-sample | phylo-informed-sample | 20 | 20 | 155 | 2.31e-01 | 5.13e-01 | ns |
| lexicase | 0.1 | elite_true_agg_score | down-sample | down-sample-ancestor | 20 | 20 | 400 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.1 | elite_true_agg_score | down-sample | indiv-rand-sample | 20 | 20 | 400 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.1 | elite_true_agg_score | down-sample | phylo-informed-sample | 20 | 20 | 400 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.1 | elite_true_agg_score | down-sample-ancestor | indiv-rand-sample | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.1 | elite_true_agg_score | down-sample-ancestor | phylo-informed-sample | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| lexicase | 0.1 | elite_true_agg_score | indiv-rand-sample | phylo-informed-sample | 20 | 20 | 288 | 1.70e-02 | 6.80e-02 | ns |
| tournament | 0.01 | elite_true_agg_score | down-sample | down-sample-ancestor | 20 | 20 | 400 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.01 | elite_true_agg_score | down-sample | indiv-rand-sample | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| tournament | 0.01 | elite_true_agg_score | down-sample | phylo-informed-sample | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| tournament | 0.01 | elite_true_agg_score | down-sample-ancestor | indiv-rand-sample | 20 | 20 | 0 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.01 | elite_true_agg_score | down-sample-ancestor | phylo-informed-sample | 20 | 20 | 0 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.01 | elite_true_agg_score | indiv-rand-sample | phylo-informed-sample | 20 | 20 | 177 | 5.47e-01 | 5.47e-01 | ns |
| tournament | 0.1 | elite_true_agg_score | down-sample | down-sample-ancestor | 20 | 20 | 0 | 0.00e+00 | 0.00e+00 | **** |
| tournament | 0.1 | elite_true_agg_score | down-sample | indiv-rand-sample | 20 | 20 | 0 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.1 | elite_true_agg_score | down-sample | phylo-informed-sample | 20 | 20 | 0 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.1 | elite_true_agg_score | down-sample-ancestor | indiv-rand-sample | 20 | 20 | 0 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.1 | elite_true_agg_score | down-sample-ancestor | phylo-informed-sample | 20 | 20 | 0 | 1.00e-07 | 7.00e-07 | **** |
| tournament | 0.1 | elite_true_agg_score | indiv-rand-sample | phylo-informed-sample | 20 | 20 | 251 | 1.71e-01 | 5.13e-01 | ns |
5.4 Number unique individual selected
build_plot_summary_data(
ts_summary_data,
focal_diagnostic,
"lexicase",
"avg_num_unique_selected"
)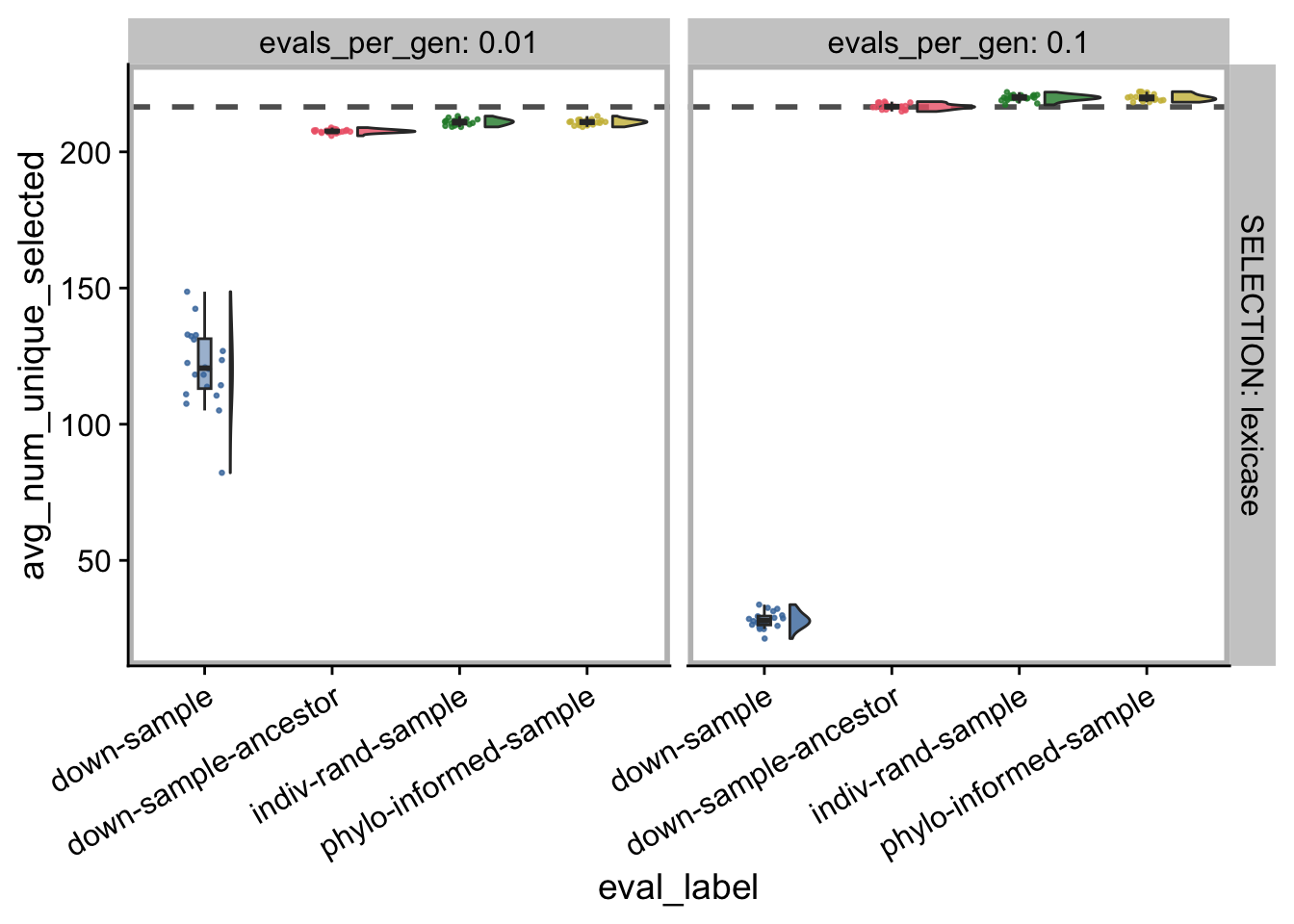
Average number selected by standard lexicase?
mean(filter(
ts_summary_data,
SELECTION == "lexicase" &
DIAGNOSTIC == "exploitation-rate" &
evals_per_gen == "1"
)$avg_num_unique_selected)## [1] 216.6185mean(filter(
ts_summary_data,
SELECTION == "lexicase" &
DIAGNOSTIC == "exploitation-rate" &
evals_per_gen == "0.1",
eval_label == "down-sample"
)$avg_num_unique_selected)## [1] 28.099mean(filter(
ts_summary_data,
SELECTION == "lexicase" &
DIAGNOSTIC == "exploitation-rate" &
evals_per_gen == "0.01",
eval_label == "down-sample"
)$avg_num_unique_selected)## [1] 120.74555.5 Manuscript figures
Figures customized / cleaned up for the manuscript.
build_final_score_manuscript_plot <- function(
selection,
subsample_rate
) {
# Extract median values for max aggregate score at same evaluation level
# as sampling regimes
max_eval <- max(
filter(exploit_ts_data, evals_per_gen == subsample_rate)$evaluations
)
full_eval_steps <- as.numeric(
levels(
as.factor(
filter(exploit_ts_data, eval_label == "full" & evaluations >= max_eval)$evaluations # nolint: line_length_linter.
)
)
)
full_eval <- full_eval_steps[which.min( full_eval_steps - max_eval )]
full_median_score_evals <- median(
filter(
exploit_ts_data,
SELECTION == selection & eval_label == "full" & evaluations == full_eval
)$max_agg_score
)
plot <- exploit_summary_data %>%
filter(
eval_label != "full" &
SELECTION == selection &
evals_per_gen == subsample_rate
) %>%
ggplot(
aes(
x = eval_label,
y = elite_true_agg_score,
fill = eval_label
)
) +
geom_hline(
yintercept = full_median_score_evals,
size = 1.0,
alpha = 0.7,
color = "black",
linetype="dashed"
) +
geom_flat_violin(
position = position_nudge(x = .2, y = 0),
alpha = .8,
adjust = 1.5
) +
geom_point(
mapping = aes(color = eval_label),
position = position_jitter(width = .15),
size = .5,
alpha = 0.8
) +
geom_boxplot(
width = .1,
outlier.shape = NA,
alpha = 0.5
) +
scale_y_continuous(
name = "Aggregate score",
limits = c(0, 10010)
) +
scale_x_discrete(
name = "Subsampling regimes",
breaks = c("down-sample", "down-sample-ancestor", "indiv-rand-sample", "phylo-informed-sample"),
labels = c("DS", "DS+EST", "IRS", "ABS")
) +
scale_fill_bright() +
scale_color_bright() +
theme(
legend.position = "none",
# axis.text.x = element_text(
# angle = 30,
# hjust = 1
# ),
)
return(plot)
}Build time series manuscript plot:
build_score_over_time_manuscript_plot <- function(
selection,
subsample_rate
) {
max_eval <- max(
filter(exploit_ts_data, evals_per_gen == subsample_rate)$evaluations
)
full_eval_steps <- as.numeric(
levels(
as.factor(
filter(exploit_ts_data, eval_label == "full" & evaluations >= max_eval)$evaluations # nolint: line_length_linter.
)
)
)
full_eval <- full_eval_steps[which.min( full_eval_steps - max_eval )]
data <- exploit_ts_data %>%
filter(
SELECTION == selection &
evals_per_gen == subsample_rate
) %>%
mutate(
sampling_level_label = subsample_rate
)
full_diag_data <- exploit_ts_data %>%
filter(
SELECTION == selection & eval_label == "full" & evaluations <= full_eval
) %>%
mutate(
# Ensure that median line will sit in same facet
sampling_level_label = subsample_rate
)
plot <- data %>%
filter(
eval_label != "full"
) %>%
ggplot(
aes(
x = evaluations,
y = max_agg_score
)
) +
stat_summary(
geom = "line",
fun = mean,
aes(
color = eval_label
)
) +
stat_summary(
geom = "ribbon",
fun.data = "mean_cl_boot",
fun.args = list(conf.int = 0.95),
alpha = 0.2,
linetype = 0,
aes(
color = eval_label,
fill = eval_label
)
) +
scale_y_continuous(
name = "Aggregate score",
limits = c(0, 10010)
) +
scale_x_continuous(
name = "Evaluations"
) +
scale_fill_bright(
labels=c(
"Down-sampling (DS), no estimation",
"Down-sampling + Estimation (DS+EST)",
"Individualized random sampling (IRS)",
"Ancestor-based sampling (ABS)"
)
) +
scale_color_bright(
labels=c(
"Down-sampling (DS), no estimation",
"Down-sampling + Estimation (DS+EST)",
"Individualized random sampling (IRS)",
"Ancestor-based sampling (ABS)"
)
) +
theme(
legend.position = "none"
) +
stat_summary(
data = full_diag_data,
geom = "line",
fun = median,
linetype = "dashed",
color = "black"
)
return(plot)
}Build plots of final scores (after fixed number of evaluations)
plot_final_lex_01 <- build_final_score_manuscript_plot(
"lexicase",
"0.01"
)
plot_final_lex_10 <- build_final_score_manuscript_plot(
"lexicase",
"0.1"
)
plot_final_tourn_01 <- build_final_score_manuscript_plot(
"tournament",
"0.01"
)
plot_final_tourn_10 <- build_final_score_manuscript_plot(
"tournament",
"0.1"
)Build time series plots (with evaluations on x-axis)
plot_ts_lex_01 <- build_score_over_time_manuscript_plot(
"lexicase",
"0.01"
)
plot_ts_lex_10 <- build_score_over_time_manuscript_plot(
"lexicase",
"0.1"
)
plot_ts_tourn_01 <- build_score_over_time_manuscript_plot(
"tournament",
"0.01"
)
plot_ts_tourn_10 <- build_score_over_time_manuscript_plot(
"tournament",
"0.1"
)5.5.1 Lexicase selection manuscript figure
txt_size <- 16
legend <- get_legend(
plot_ts_lex_01 +
guides(
color = guide_legend(nrow = 2, title = "Subsampling regime:"),
fill = guide_legend(nrow = 2, title = "Subsampling regime:")
) +
theme(
legend.position = "bottom",
legend.text = element_text(size = txt_size - 2),
legend.title = element_text(size = txt_size)
)
)
grid <- plot_grid(
plot_ts_lex_01 +
labs(title = "1% Subsampling") +
theme(
axis.text.x = element_text(size = txt_size-2),
axis.text.y = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size),
axis.title.y = element_text(size = txt_size)
),
plot_final_lex_01 +
theme(
axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank(),
plot.margin = margin(0, 0, 0, 1, "cm"),
axis.text.x = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size)
),
plot_ts_lex_10 +
labs(title = "10% Subsampling") +
theme(
axis.text.x = element_text(size = txt_size-2),
axis.text.y = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size),
axis.title.y = element_text(size = txt_size)
),
plot_final_lex_10 +
theme(
axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank(),
plot.margin = margin(0, 0, 0, 1, "cm"),
axis.text.x = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size)
),
nrow = 2,
ncol = 2,
align = "h",
labels = c("a", "b", "c", "d"),
label_size = 18,
rel_widths = c(1.3, 1, 1.3, 1)
)
grid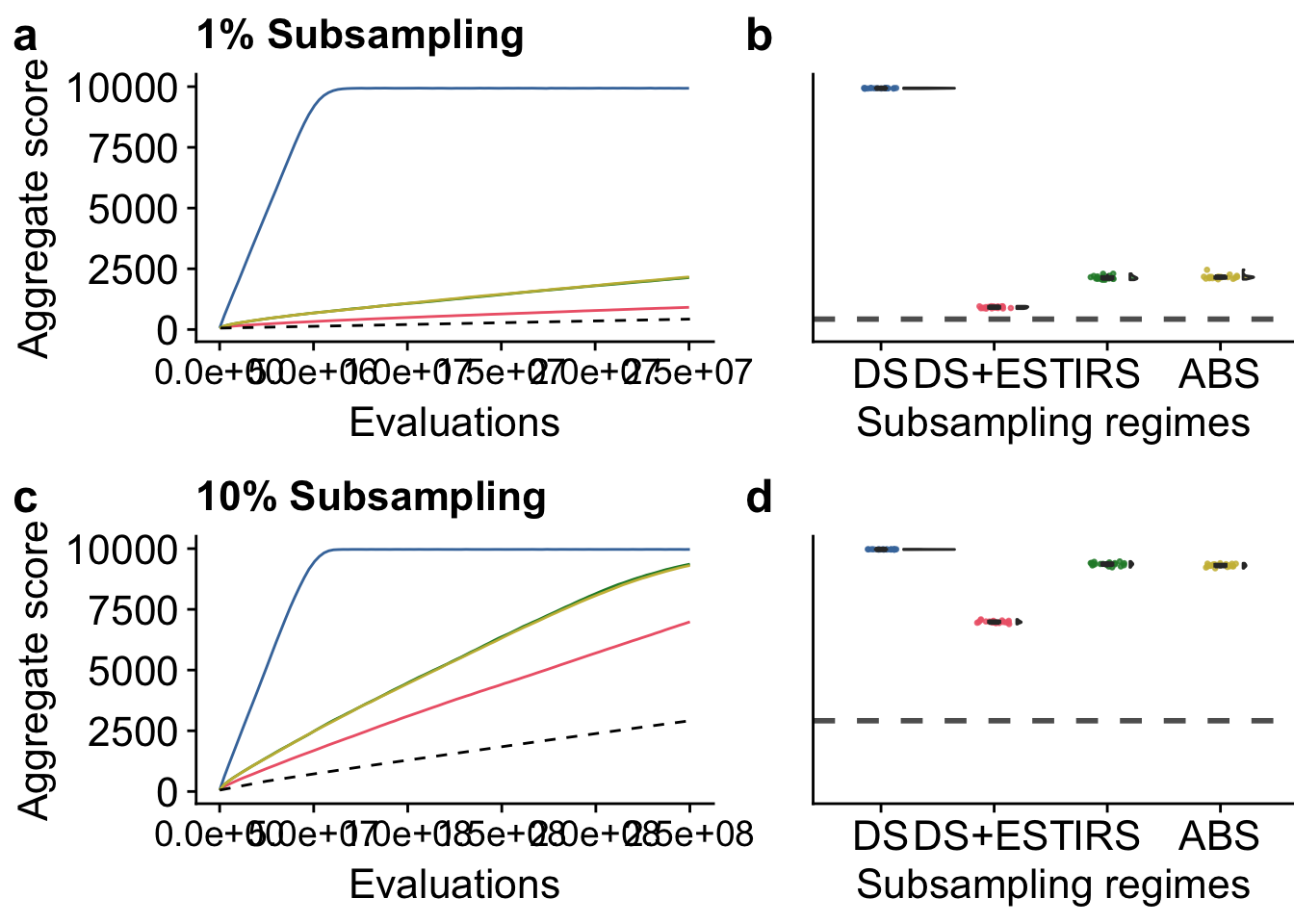
lex_fig <- plot_grid(
grid,
legend,
nrow = 2,
ncol = 1,
rel_heights = c(1, 0.05)
)
# lex_fig
save_plot(
filename = paste0(plot_directory, "2023-12-28-exploit-lex-fig.pdf"),
plot = lex_fig,
base_width = 10,
base_height = 8,
dpi = 600
)5.5.2 Tournament selection manuscript figures
legend <- get_legend(
plot_ts_tourn_01 +
guides(
color = guide_legend(nrow = 2, title = "Subsampling regime:"),
fill = guide_legend(nrow = 2, title = "Subsampling regime:")
) +
theme(
legend.position = "bottom",
legend.text = element_text(size = txt_size - 2),
legend.title = element_text(size = txt_size)
)
)
grid <- plot_grid(
plot_ts_tourn_01 +
labs(title = "1% Subsampling") +
theme(
axis.text.x = element_text(size = txt_size-2),
axis.text.y = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size),
axis.title.y = element_text(size = txt_size)
),
plot_final_tourn_01 +
theme(
axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank(),
plot.margin = margin(0, 0, 0, 1, "cm"),
axis.text.x = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size)
),
plot_ts_tourn_10 +
labs(title = "10% Subsampling") +
theme(
axis.text.x = element_text(size = txt_size-2),
axis.text.y = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size),
axis.title.y = element_text(size = txt_size)
),
plot_final_tourn_10 +
theme(
axis.text.y = element_blank(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank(),
plot.margin = margin(0, 0, 0, 1, "cm"),
axis.text.x = element_text(size = txt_size),
axis.title.x = element_text(size = txt_size)
),
nrow = 2,
ncol = 2,
align = "h",
labels = c("a", "b", "c", "d"),
label_size = 18,
rel_widths = c(1.3, 1, 1.3, 1)
)
tourn_fig <- plot_grid(
grid,
legend,
nrow = 2,
ncol = 1,
rel_heights = c(1, 0.05)
)
tourn_fig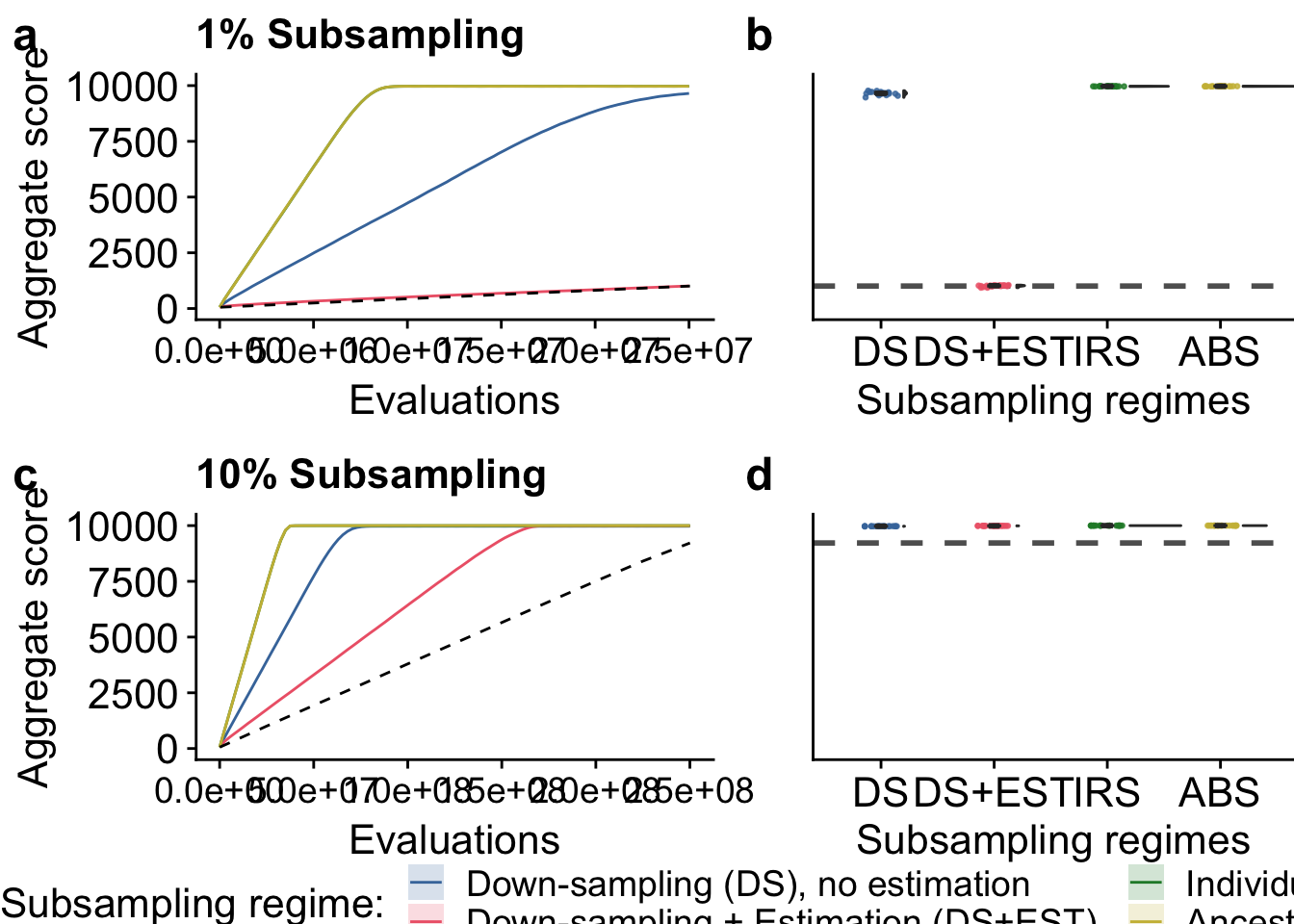
save_plot(
filename = paste0(plot_directory, "2023-12-28-exploit-tourn-fig.pdf"),
plot = tourn_fig,
base_width = 10,
base_height = 8,
dpi = 600
)